我用 10 周做了一个 86K 的 AI Skill 目录。为什么现在要转向。
Agent Skills Hub 用 10 周收录了 86,000 个开源 AI skill。流量涨得飞快,月收入却是 $0。然后我访谈了 15 个用户 —— 才意识到「发现」从来不是问题。
诚实的承认
我在 2026 年 3 月 8 日上线了 Agent Skills Hub。10 周后,它收录了 86,000+ 个开源 AI agent skill 和 MCP server,对每一个都做了 10 个维度的质量评分,并且每 8 小时刷新一次整个目录。
SEO 流量来得比我预期快 —— 10 周内 Google Search Console 累计 6 万+ 曝光,分类页开始在一些真实搜索词上排到第一页。
而这一切带来的月收入,恰好是 $0。
这篇文章不是抱怨,恰恰相反。一个人能在 10 周里建出一个 86,000 条的目录 —— 这件事本身就暴露了问题。建目录很快。目录就是不值钱。下面是我学到的,以及 Hub 接下来去哪。
目录陷阱
让我起步的那个直觉,简单且错误:收录越多 skill = 价值越高。如果目录最大、最新,那它就是护城河,对吧?
不对。目录 —— npm、App Store、Product Hunt —— 是入口,不是产品。没人会为「能浏览目录」这件事付钱给目录。目录变现的是它下游的东西:托管、分发、信任、推荐位。清单本身免费,因为清单本身造起来很便宜。在我这里,是一个人 10 周的时间。
更糟的是,纯目录会把你卡在中间。Hub 太技术,做不成消费级 SEO 工具站(那种靠百万月访问量赚广告费的);又太轻量,做不成严肃的企业平台。它服务的是开源生态的供给端 —— 那些发布 skill 的开发者 —— 而这群人,定义上就不付费。他们是贡献者。
15 个访谈告诉我的
所以我停止了猜测,做了结构化访谈:5 个独立开发者、5 个企业决策者、5 个 skill 创作者,覆盖中美德三地 —— 行业涵盖科技、医疗、汽车、物流。
这三类人在几乎所有事上都意见相左。但有一点他们完全一致,而且不是我预期的那一点:
「发现 skill 不难。评估它、验证它、安全部署它 —— 才是所有摩擦所在。」
一位独立开发者兼 B2B SaaS 创始人说得很直白:「靠谱不是能用,而是出错时不会系统瘫痪。少踩一个坑,比多一个功能值钱太多。」
一位大型科技企业的工程 VP:「真正的卡点是身份认证、最小权限、失败回滚机制。没有这些,什么都别想上线。」
一位德国汽车行业的技术决策者:「合规和可审计性不是排名问题,是前置硬要求。」
这个模式无法忽视。人们付费是为了消除风险,不是为了发现 skill。 发现只是入场券 —— 是门槛,不是价值。那些访谈里,每一分钱的付费意愿都站在安全、回滚、审计后面。而我的目录,恰好解决的是这条链路里没人愿意付费的那一环。
漏洞问题
然后我把 Hub 自己的扫描器对准了它一直在礼貌地编目的那个生态。结果令人不安。
独立研究给出的 agent skill 漏洞率是 26.1%(Liu et al. 2026,arXiv:2601.10338)—— 提示词注入、凭证泄露、沙箱逃逸风险。我们自己对全库的规则扫描更保守,但仍把每 32 个被评级 skill 里的 1 个标为直接不安全。无论哪个口径,这都不是边角案例。
越细看越糟。连接 5 个各含约 30 个工具的 MCP server,agent 还没干任何有用的事,就可能烧掉 100K+ token 的上下文。而 stdio 传输层有个毛病:出错时返回 200 OK —— 这意味着模型会在一个它从未被告知的失败之上,愉快地产生幻觉。
这一段重新定义了一切。「Hub 有 86,000 个 skill」不是价值主张。「这 86,000 里,哪些是真正能安全上生产的」—— 这才是。 这个漏洞率对 Hub 不是坏消息,是护城河。一个通过了真实审计的 skill,带有稀缺的、可证明的「可信溢价」。这个溢价,是企业愿意付费的,也是创作者愿意花钱去赢得的。
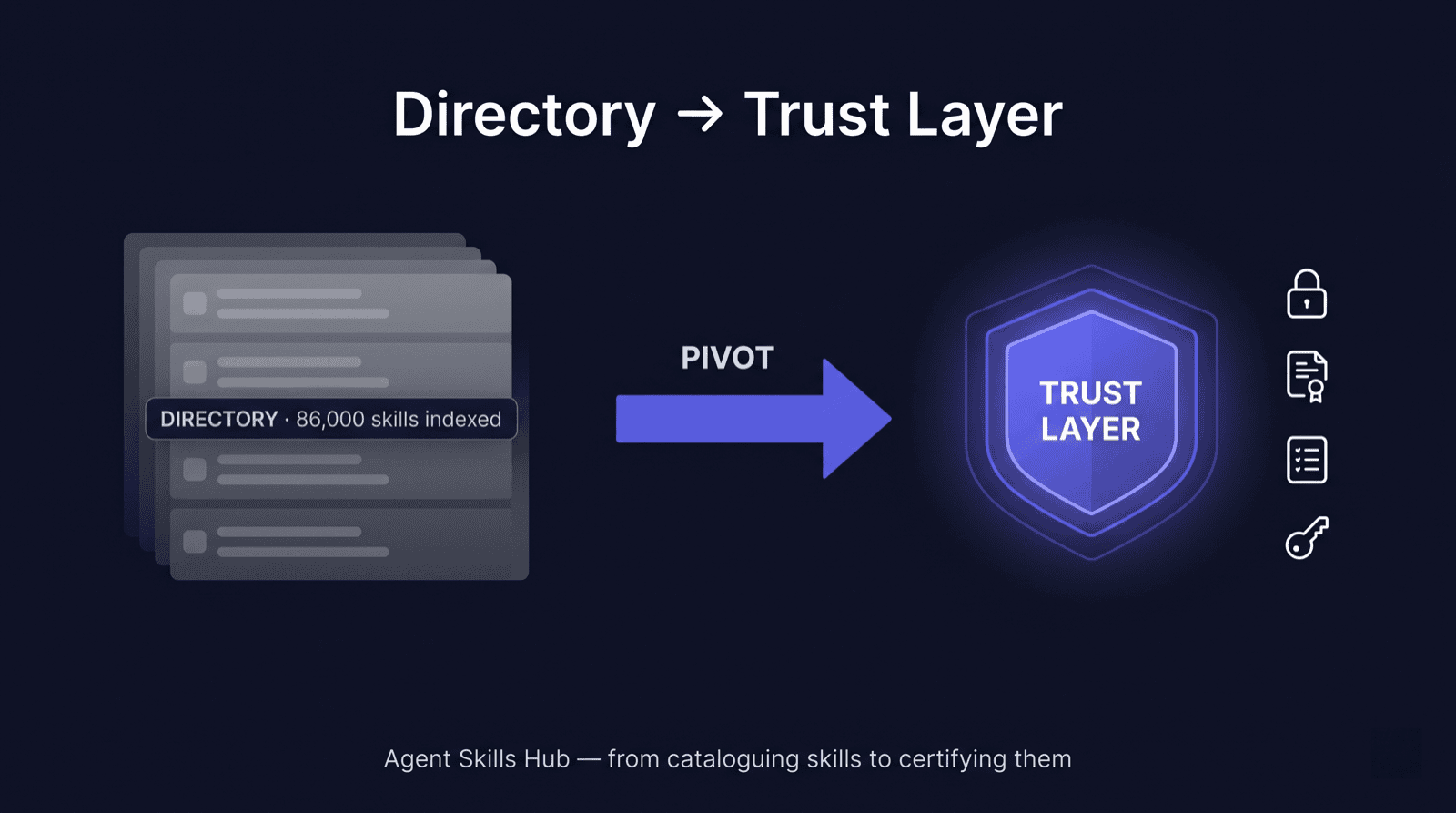
新定位
所以,从今天起,Agent Skills Hub 不再把自己描述为「目录」。新的那句话 —— 此后每一个页面、每一次 pitch、每一个决策都锚定它:
Agent Skills Hub —— AI Agent 与 MCP 部署的信任层(Trust Layer)。
具体来说,这意味着 Hub 坐在你的开发者和你的生产环境之间,提供四样东西:
- 部署前沙箱 —— 用脱敏的、生产形态的数据,在隔离环境里跑一个 skill,遇到第一个异常就触发 kill switch。
- 合规证据包 —— 自动生成的 PDF,把每个 skill 映射到 SOC 2 控制项、ISO/IEC 42001 对齐、EU AI Act 2026 风险分级。就是你递给审计师的那份文件。
- 全链路审计日志 —— 每个 tool call、数据流、错误回放,可导出到你的 SIEM。
- SSO/SCIM + 细粒度 RBAC —— 对接 Okta、Auth0、Azure AD;skill 级别权限。
设计原则直接来自访谈:嵌入企业既有流程 —— IAM、CI/CD、SIEM —— 而不是要求企业去适应又一个新平台。
什么变,什么不变
如果你一直把 Hub 当免费目录用,对你来说几乎什么都不变:
| 不变 | 新增 / 升级 |
|---|---|
| 86K+ 目录永久免费 | /enterprise/ —— 企业审计 + 合规证据包 |
| 每 8 小时刷新 | Verified Creator 升级为技术深度审计 |
| 开源、MIT、评分透明 | 蓝皮书重构为硬指标驱动 |
蓝皮书尤其需要诚实。用户告诉我,他们希望它剔除营销型排行榜,重建在可复现的硬数据之上 —— 漏洞修复率、平均恢复时间(MTTR)、回滚率、延迟分布。建立在感性投票上的排行榜没有商业价值。建立在日志上的基准测试才有。所以,就这么重建。
18 个月路线图
三个阶段,按「谁先付费」排序:
- Phase 1(0–3 月)—— 信任基础设施。 /enterprise/ MVP:SSO/SCIM、沙箱、审计日志导出、合规证据包。加上 Verified Creator 的技术深度审计升级。目标:首批 3–5 家企业 POC。
- Phase 2(4–9 月)—— 开发者工具链。 IDE 插件(发现、试跑、版本锁定一体化),以及 Arena 重构为基准测试平台 —— 用自动化指标取代匿名投票。
- Phase 3(10–18 月)—— 创作者经济 + 国际合规。 多模型创作者变现,加上 Hub 自身的 SOC 2 Type II 和 ISO/IEC 42001 认证。
我的请求
如果你的团队在 production 跑 AI agent —— 而且你被合规卡过 launch、出过提示词注入事故、或者干脆没有一个干净的办法在 MCP server 上生产前 audit 它 —— 我想跟你聊聊。
不是推销。是想搞懂。一个 30 分钟的通话,我们一起走一遍你当前的配置,在挂电话前我给你指出三个立即存在的风险。
这篇博客本身就是 build in public 的一部分。我会在每个阶段结束时发一份诚实的复盘 —— 什么有用、什么没用、真实数字是多少。下一篇复盘会告诉你这次转向到底对不对。
Agent Skills Hub 是开源项目(MIT)。86K 目录永久免费。方法论与数据快照记录在 github.com/ZhuYansen/agent-skills-hub。